Here we will create a new SVM named svm1 on cluster and will configure it to serve out a volume over NFS and CIFS. We will be configuring two NAS data LIFs on the SVM, one per node in the cluster.
Step:1
Open System manager => Storage virtual machines => Click "create"
Need to provide SVM name, Data protocols, Root aggregate & DNS details,

Step:2
In this step need to specify data interfaces (LIF) and CIFS server details,

Step:3
Specify the password for an SVM specific administrator account for the SVM, which can then be used to delegate admin access for just this SVM.

Step:4
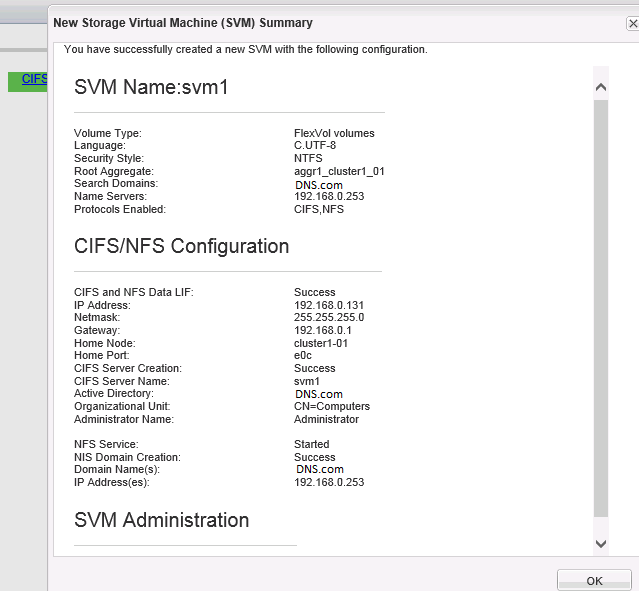
New Storage Virtual Machine Summary window opens displaying the details of the newly created SVM.
Step:5
The SVM svm1 is now listed under cluster1 on the Storage Virtual Machines tab. The NFS and CIFS protocols are showing in right panel,which indictates that those protocols are enabled for the selected SVM svm1.

Creating Vserver through CLI:
Create Vserver using "vserver create" command,

We are not yet any LIFs defined for the SVM svm1. Create the svm1_cifs_nfs_lif1 data LIF for svm1:

Configure the DNS domain and nameservers for the svm1,

That's it :)
Step:1
Open System manager => Storage virtual machines => Click "create"
Need to provide SVM name, Data protocols, Root aggregate & DNS details,
Step:2
In this step need to specify data interfaces (LIF) and CIFS server details,
Step:3
Specify the password for an SVM specific administrator account for the SVM, which can then be used to delegate admin access for just this SVM.
Step:4
New Storage Virtual Machine Summary window opens displaying the details of the newly created SVM.
Step:5
The SVM svm1 is now listed under cluster1 on the Storage Virtual Machines tab. The NFS and CIFS protocols are showing in right panel,which indictates that those protocols are enabled for the selected SVM svm1.
Creating Vserver through CLI:
Create Vserver using "vserver create" command,
We are not yet any LIFs defined for the SVM svm1. Create the svm1_cifs_nfs_lif1 data LIF for svm1:
Configure the DNS domain and nameservers for the svm1,
That's it :)